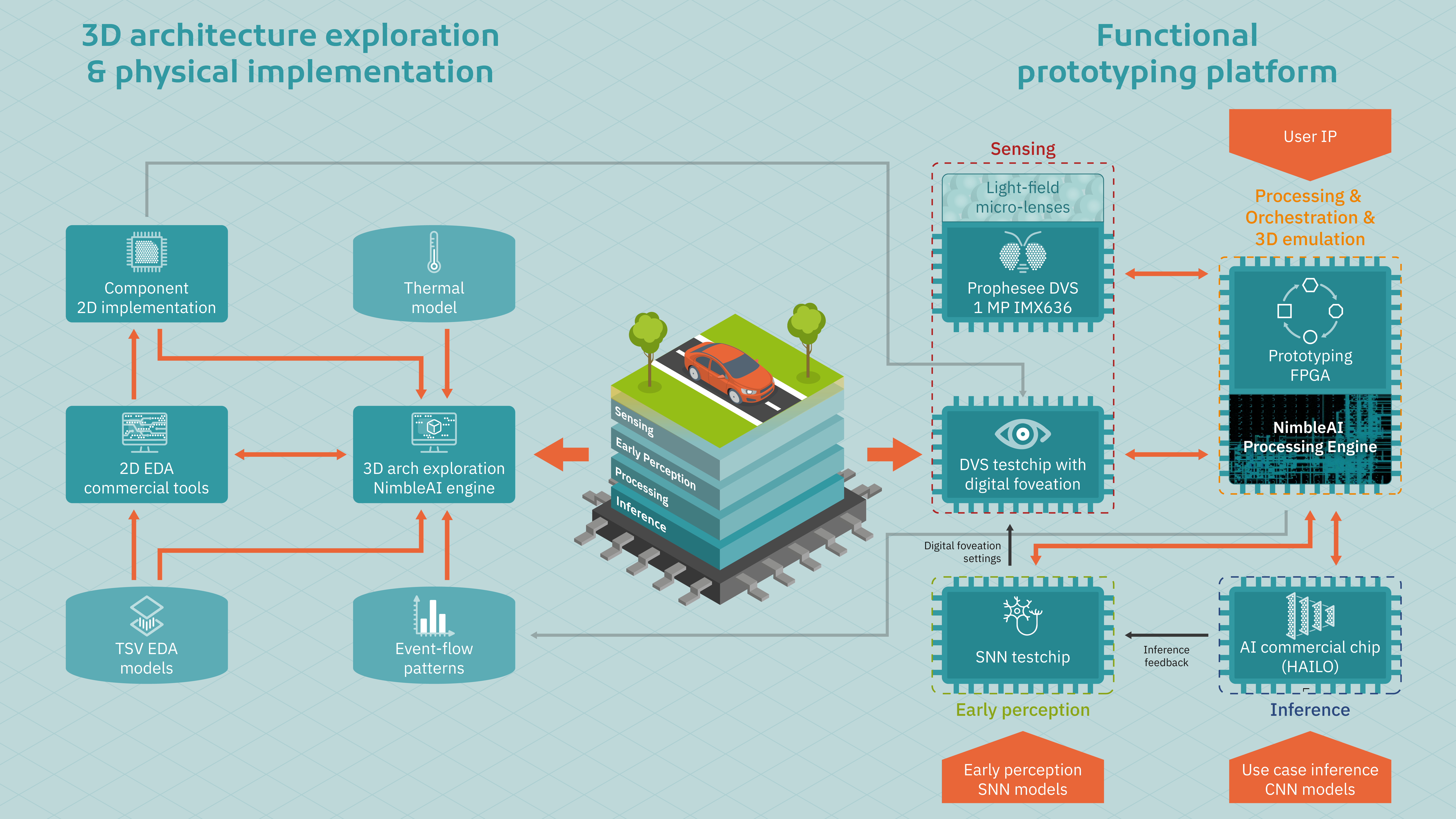
NimbleAI explores system-level trade-offs in a 3D integrated sensing-processing neuromorphic architecture that can be customised –at design time or after deployment– to a broad range of computer vision applications and a great variety of deployment environments.
The system-level approach is combined with specific improvements in selected components where significant energy efficiency margins are foreseen, or novel capabilities are envisioned. Since manufacturing a full 3D testchip is prohibitively expensive, the project will prototype key components via small-scale 2D stand-alone testchips. This cost-effective use of silicon allows us to readjust direction during project execution to produce silicon-proven IP and high confidence research conclusions.
To enable the global research community to use our results, the project will deliver a prototype of the 3D integrated sensing-processing architecture with the corresponding programming tools. The prototype will be flexible to accommodate user IP and will combine commercial neuromorphic chips and NimbleAI testchips.
Perceiving a 3D world from a neuromorphic 3D silicon architecture

In nature:
The retina continuously senses light and encodes the changing surrounding environment in a way that is manageable for the brain.
In our chip:
The top layer in the NimbleAI 3D architecture senses light and delivers meaningful and sustainable visual event flows to downstream processing and inference engines in the interior layers to achieve efficient end-to-end cognition.



Sense light and depth
NimbleAI adopts the biological data economy principle systematically at different levels, starting with the light-electrical sensing interface.
Dynamic vision sensing (DVS)
Sensor pixels generate visual events ONLY if significant light brightness changes are detected, mimicking the functioning of rods in the retina. Hence, DVS visual events reflect the edges of moving objects, while noisy events are generated in the static background.
Digital foveation
Pixels can be dynamically grouped and ungrouped to allocate different resolution levels across sensor regions. This mimicks the foveation mechanism in eyes, which allows foveated regions to be seen in greater detail (e.g. car) than peripheral regions (e.g. trees). Digital foveation is to be driven by selective attention and optical flow estimations.
Light-field-enabled DVS with 3D perception and digital foveation
The NimbleAI sensor enables depth perception by capturing directional information of incoming light by means of light-field micro-lenses inspired by the insect compound eye. The origin of light rays is calculated by triangulating disparities from neighbour views formed by the micro-lenses. 3D visual scenes are thus encoded in the form of sparse visual events that include: pixel position (x,y), depth information (z), timestamp (t), polarity (p) and foveated region id.
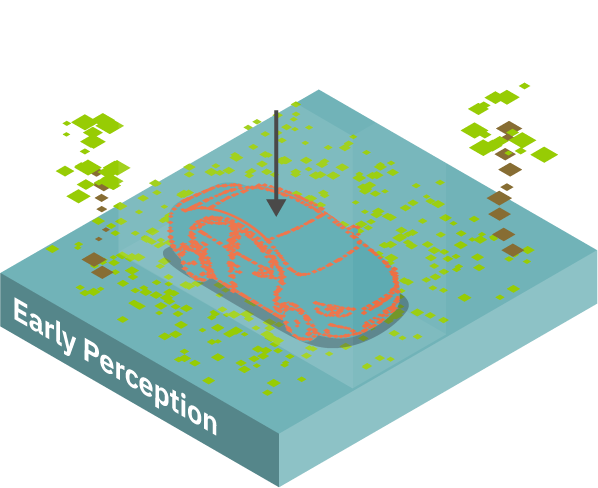
Ignore? or recognise
An always-on early perception stage continuously analyses the sensed visual events in a spatio-temporal mode to extract the optical flow and identify and select ONLY salient regions with high-value or critical information for further processing in high-resolution (foveated regions). It is also expected that depth perception enabled by light-field vision will play a major role in selecting salient regions to foveate: nearby objects are typically more critical than those in the background. The algorithms used in this stage are carefully designed to be ultra-energy efficient, inspired by selective attention and spike-based visual processing in the retina (spiking neural networks = SNNs).
The expectation is that by investing some computing power and energy to gain valuable situational awareness early in the inference pipeline, this stage will reduce the amount of data to be processed, saving lots of energy by doing that.
Two converging approaches are envisioned to capture and replicate in silicon the biological energy-saving early visual perception mechanisms:
Top-down:
attentional activity of human drivers in real-world scenarios are being recorded (via eye tracking) and used to train SNNs.
Bottom-up:
models and topologies of neural circuits in minuscule brains of bees are being explored to design simple artificial SNNs that deliver useful types of attentional performance and optical flow estimations (processing data sensed by compound eyes).

Eventually we would like to accomplish the key principle of biological visual systems: information-efficiency.
Every sensed data should be worth being processed
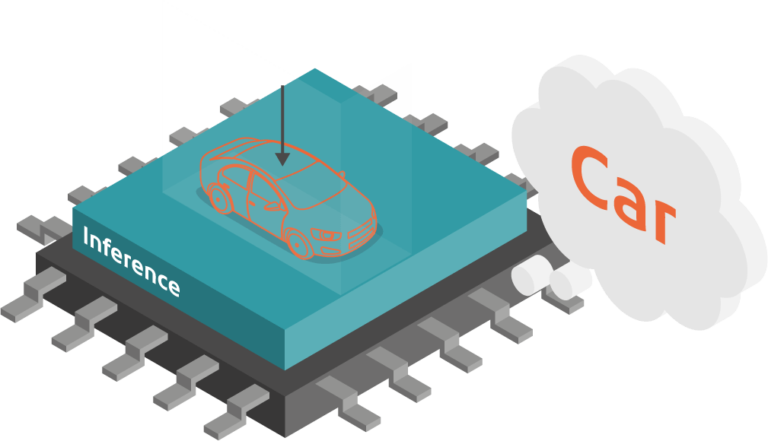
Process efficiently
Downstream inference and processing engines analyse visual events in selected salient regions on-demand to achieve end-to-end cognition using industry standard inference models (convolutional neural networks = CNNs) and other non-AI processing kernel. Inference models and processing kernels are tailored to each salient region properties, including size, shape and resolution, as well as to meet the processing latency required by movement patterns of objects in those regions. Format and properties of incoming visual event flows are adapted in the processing engine to best exploit the optimisation mechanisms implemented in the inference engine.
The processing engine relies on using in-memory computing blocks, customisable RISC-V CPUs and programmable logic (eFPGA) to allow after deployment hardware updates. The inference engine implements a dataflow architecture that exposes and exploits sparsity properties of incoming visual event flows, generating neural events ONLY if there are significant changes in neuron states. Time and performance-driven visual to neural event conversion techniques are being explored to match temporal dynamics in the visual scene with minimal energy use at each time.
The inference engine implements a hardware mechanism to virtually augment the effective count of neurons integrated in limited silicon area and run the novel concept of Virtual Neural Networks. This is achieved by enabling store and restore network parameters and data on a 3D memory hierarchy that uses high-density RRAM cells. The latter memory hierarchy implements pre-fetching and synchronisation logic integrated in the pipelines of the inference cores to minimise impact on dataflow performance.
Adaptive visual pathways
Visual pathways span the sensor areas occupied by salient regions and include dedicated paths to route visual events to downstream inference and processing engines. Visual pathways are dynamically created (and destroyed) as new salient regions are detected. They are independently configured (from sensor to processing) at optimal accuracy and latency levels for each region, as dictated either explicitly by the user or automatically by the SNNs in the early perception stage for improved autonomous performance.
The early perception SNNs and downstream inference and processing engines reinforce each other along visual pathways by exchanging feedback inference results and performance analytics to become more efficient in sensing and processing dynamic visual scenes as these get more familiar (online learning).
Hence, NimbleAI leverages state-of-the-art SNNs for optimised energy-efficiency and event-driven CNNs for usability and productivity as they are backed by popular frameworks such as TensorFlow. At runtime, a partial knowledge transfer (via online learning) occurs from downstream user-trained CNNs to upstream SNNs to optimise the overall system performance.
This unique optimisation approach is opposed to the current situation in which performance and accuracy trade-offs are often presented to users as a necessity at the design phase that remains fixed in deployment. NimbleAI does not oblige users to choose between accuracy or efficiency. Instead, it offers to the users a series of novel runtime system-level optimisation strategies to be continuously refined by means of online learning and applied directly on the user-trained models.
3D integrated silicon
NimbleAI envisions a 3D integrated architecture to deliver high bandwidth communication for:
(1) paralell processing of selected salient regions and event flows along visual pathways; and
(2) increasing the effective neuron count in the inference engine via stacked RRAM layers with dedicated low-latency access to computing resources to execute virtual neural networks. Local over global connection patterns are exploited for improved efficiency: events are identified locally within the 3D architecture with few id bits, while additional bits are added dynamically to infrequent events that move inter-region.
NimbleAI is developping a 3D EDA tool that supports novel co-design methodologies covering technology-aware 3D architecture exploration across layers and integration to physical implementation. The tool considers the geometry of the micro-lenses and associated visual event generation and communication patterns, as well as thermal and technology-related aspects, such as process technology and component size trade-offs. The EDA tool will help make optimal decisions related to layer floor-planning, vertical arrangement of layers, and location of through silicon vias (TSVs) as well as carry out pre-manufacturing checks.
The combination of a 3D EDA tool and novel neuromorphic IP brings a powerful and flexible complete solution to help customise the NimbleAI 3D architecture to meet different application requirements.
The NimbleAI 3D architecture will be characterised by combining data from three sources:
- Measurements in 2D testchips of selected NimbleAI components manufactured in the project or by partners that have previsions to manufacture silicon within the project timeframe.
- Power, performance and area results provided by third-party physical implementation and analysis 2D EDA tools as well as the NimbleAI 3D EDA tool.
- Functional traces collected when running use case algorithms in the prototyping platform below, which integrates commercial neuromorphic chips and NimbleAI testchips.